Building a Q&A app capable of answering questions related to your enterprise documents using AWS Bedrock, AWS Kendra, AWS S3 and Streamlit
Just show me the code!
As always, if you don’t care about the post I have uploaded the source code on my Github.
A few months ago, I wrote a post about how to build a Q&A app capable of answering questions related to your private documents using OpenAI GPT-4. You can read it, in here.
To build it, I used the following services:
Azure OpenAI GPT-4Pinecone
In this post, I want to built exactly the same Q&A app, but using only AWS services (+ Streamlit for the UI).
That way, we can see and compare how the process of creating this type of apps differs when we use managed AWS services vs Azure services.
Before we start developing the app, let me revisit a couple of concepts that I believe are key when building such applications (apps that use a LLM to answer questions related to our private documents).
I’ve already discussed these topics in the “Building a Q&A app using Azure OpenAI GPT-4” post, but I think it’s necessary to emphasize these concepts.
How can an LLM respond to a question about topics it doesn’t know about?
We have two options for enabling our LLM model to understand and answer our private domain-specific questions:
- Fine-tune the LLM on text data covering the topic mentioned.
- Using Retrieval Augmented Generation (RAG), a technique that implements an information retrieval component to the generation process. Allowing us to retrieve relevant information and feed this information into the generation model as a secondary source of information.
We will go with option 2.
The RAG process might sound daunting at first, but it really is not. The process is quite simple once we try to explain it in a simple way, here’s a summary of how it works:
- Run a semantic search against your knowledge database to find content that looks like it could be relevant to the user’s question.
- Construct a prompt consisting of the data extracted from the knowledge database, followed by “Given the above content, answer the following question” and then the user’s question.
- Send the prompt through to an LLM and see what answer comes back.
In the end, all we are doing is extracting data from a database that looks like it could be relevant to the user’s question, constructing a prompt that contains the data from the database and telling the LLM model that it must create the response using only the data present in the prompt.
Here’s an example of the prompt:
Answer the following question based on the context below.
If you don't know the answer, just say that you don't know.
Don't try to make up an answer. Do not answer beyond this context.
---
QUESTION: {User Question}
---
CONTEXT:
{Data extracted from the knowledge database}
What are knowledge databases?
With RAG, the retrieval of relevant information requires an external “knowledge database”, a place where we can store and use to efficiently retrieve information.
We can think of this database as the external long-term memory of our LLM.
To retrieve information that is semantically related to our questions, we’re going to use a semantic search database.
Semantic search database
A semantic search database is a type of database that uses semantic technology to understand the meanings and relationships of words and phrases in order to produce highly relevant search results.
Semantic search is a search technique that uses natural language processing algorithms to understand the meaning and context of words and phrases in order to provide more accurate search results.
This approach is based on the idea that search engines should not just match keywords in a query, but also try to understand the intent of the user’s search and the relationships between the words used.
Overall, semantic search is designed to provide more precise and meaningful search results that better reflect the user’s intent, rather than just matching keywords. This makes it particularly useful for complex queries, such as those related to scientific research, medical information, or legal documents.
Which AWS services are we going to use?
For the Generative AI LLMs:
For the knowledge database:
The next image shows a diagram of how the AWS services are going to interact between them:
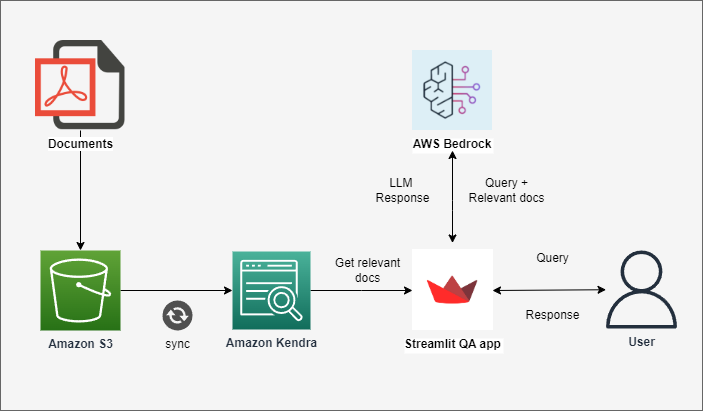
How the Q&A app works
-
The private documents are being stored in an s3 bucket.
-
The Kendra Index is configured to use an s3 connector. The Index checks the s3 bucket every N minutes for new content. If new content is found in the bucket, it gets automatically parsed and stored into Kendra database.
-
When a user runs a query through the
Streamlitapp, the app follows these steps:- Retrieves the relevant information for the given query from Kendra.
- Assembles the prompt.
- Sends the prompt to one of the available Bedrock LLMs and prints the answer that comes back.
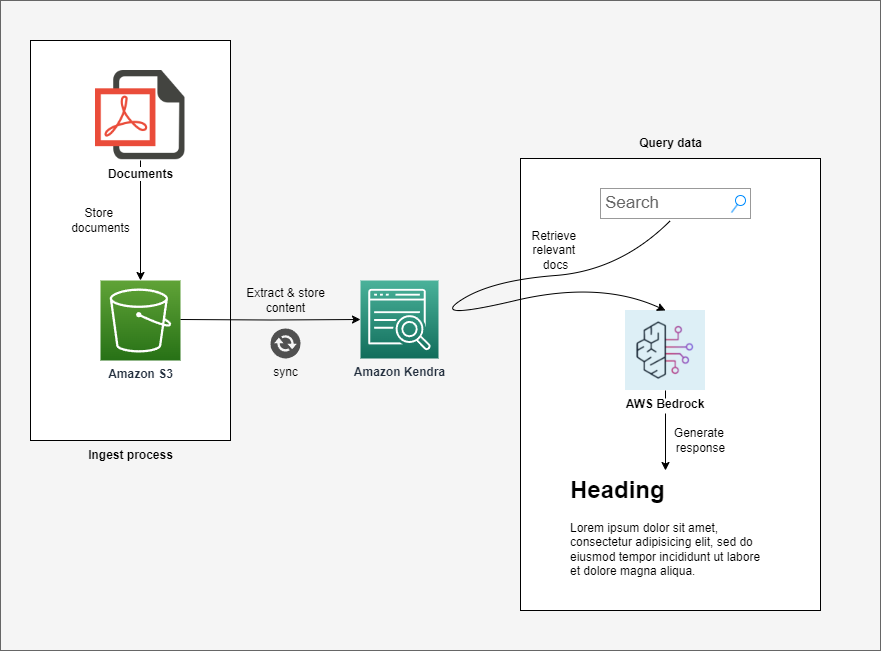
One of the best things of using AWS Kendra (paired with AWS S3) as our knowledge database is that the “Ingest Process” (see above diagram) is completely automated, you don’t have to do anything at all.
Every time we add, update, or delete a document from the S3 bucket, the content of that document is automatically parsed and stored in Kendra.
Building the Q&A app
There are a few steps required before we can begin developing the app.
1. Deploy the required AWS services
To make the app work we need to deploy the following AWS services:
- An s3 bucket for housing our private docs.
- A Kendra index with an s3 connector.
- An IAM role with the required permissions to make everything work.
You can deploy those resources as you like: using the AWS portal, AWS CDK, Terraform, Pulumi, …
⚠️ If you want to take the easy route, I have uploaded a few Terraform files to my GitHub repository that will create the required resources on your AWS account.
2. Request access to AWS Bedrock third-party LLMs
By default, in Bedrock you will have access only to the Amazon Titan LLM. To utilize any of the third-party LLMs (Anthropic, Ai21 Labs, Cohere), you must register for access separately.
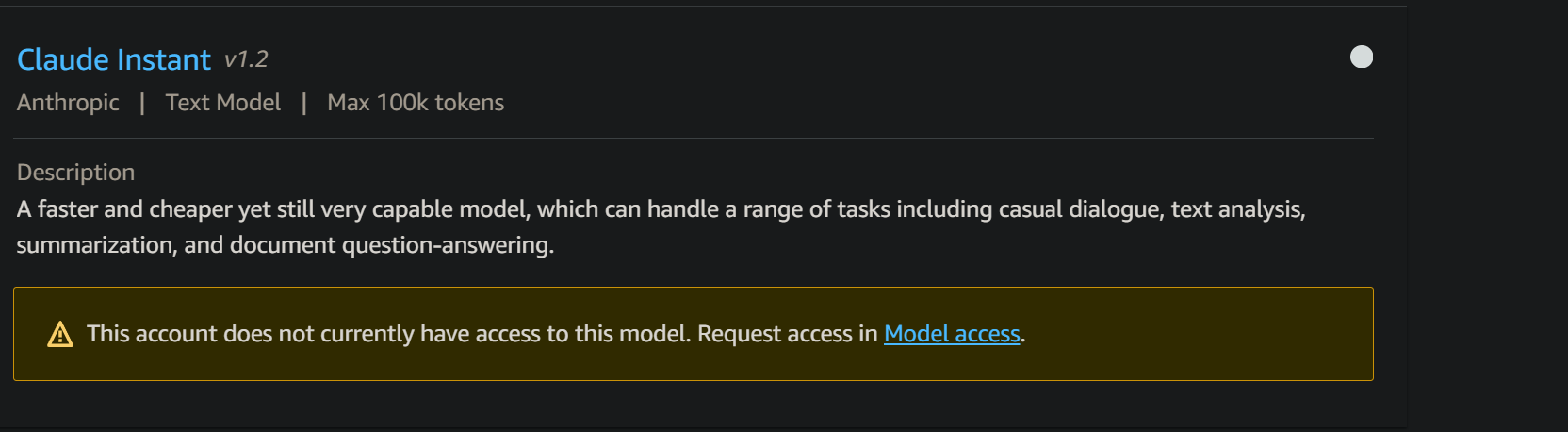
In the “Model Access” section, you have an overview of which LLMs you have access to and which ones you do not.
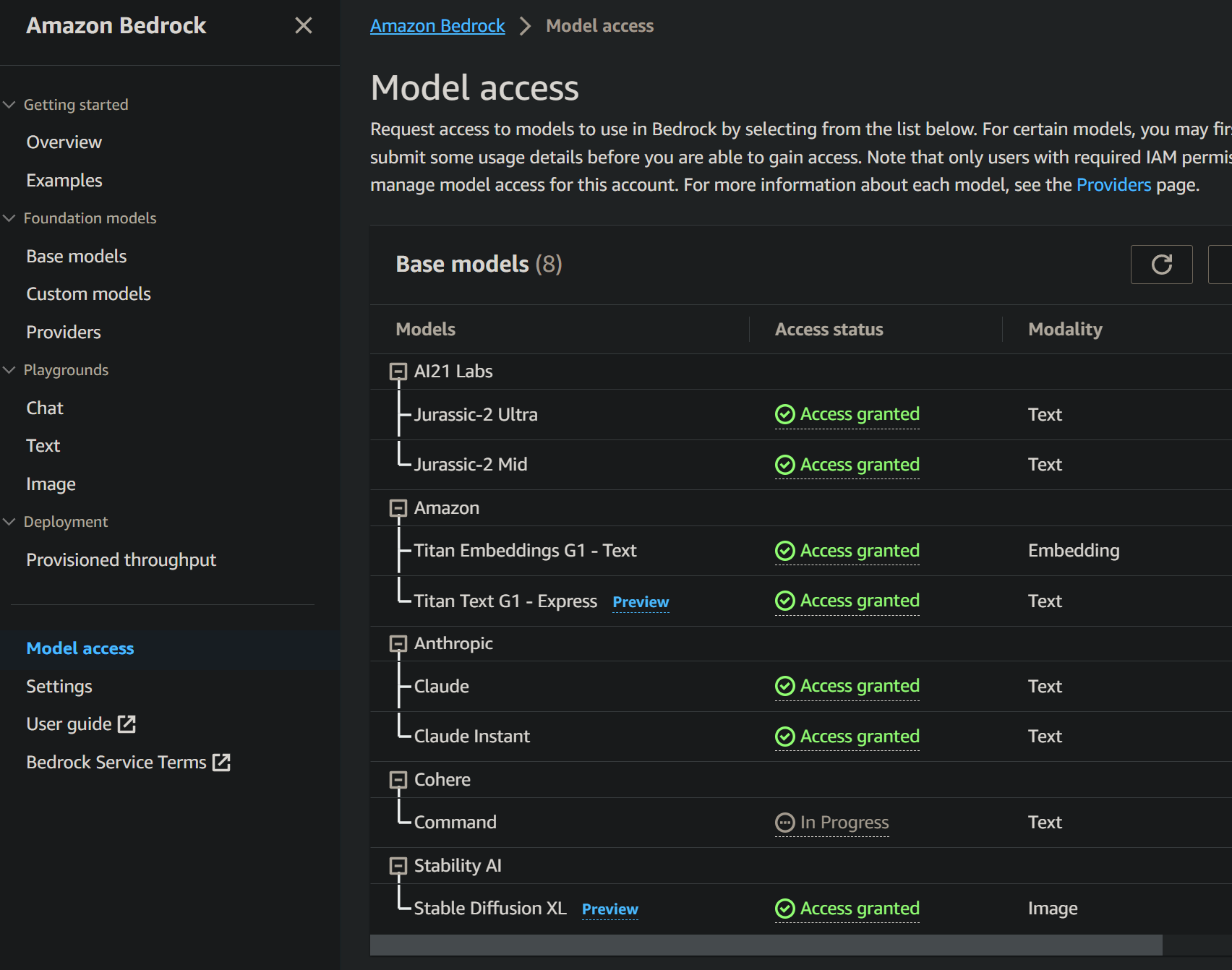
To fully use this application, you must have access to every AWS Bedrock third-paty LLMs.
3. Build the Q&A app using LangChain
⚠️ If you’re not a fan of LangChain an prefer to do everything by yourself without the aid of any third-party library, go to the next section (section 5).
In section 5, I will show you how to build the same Q&A app we’re going to build here, but using only theAWS SDK for Python.
We are going to set up a very simple UI:
- A text input field where the users can type the question they want to ask.
- A numeric input where the users can set the LLM max tokens.
- A numeric input where the users can set the LLM temperature.
- A dropdown to select which AWS Bedrock LLM we want to use to generate the response.
- And a submit button.
To build the user interface I’m using Streamlit. I decided to use Streamlit because I can build a simple and functional UI with just a few lines of Python.
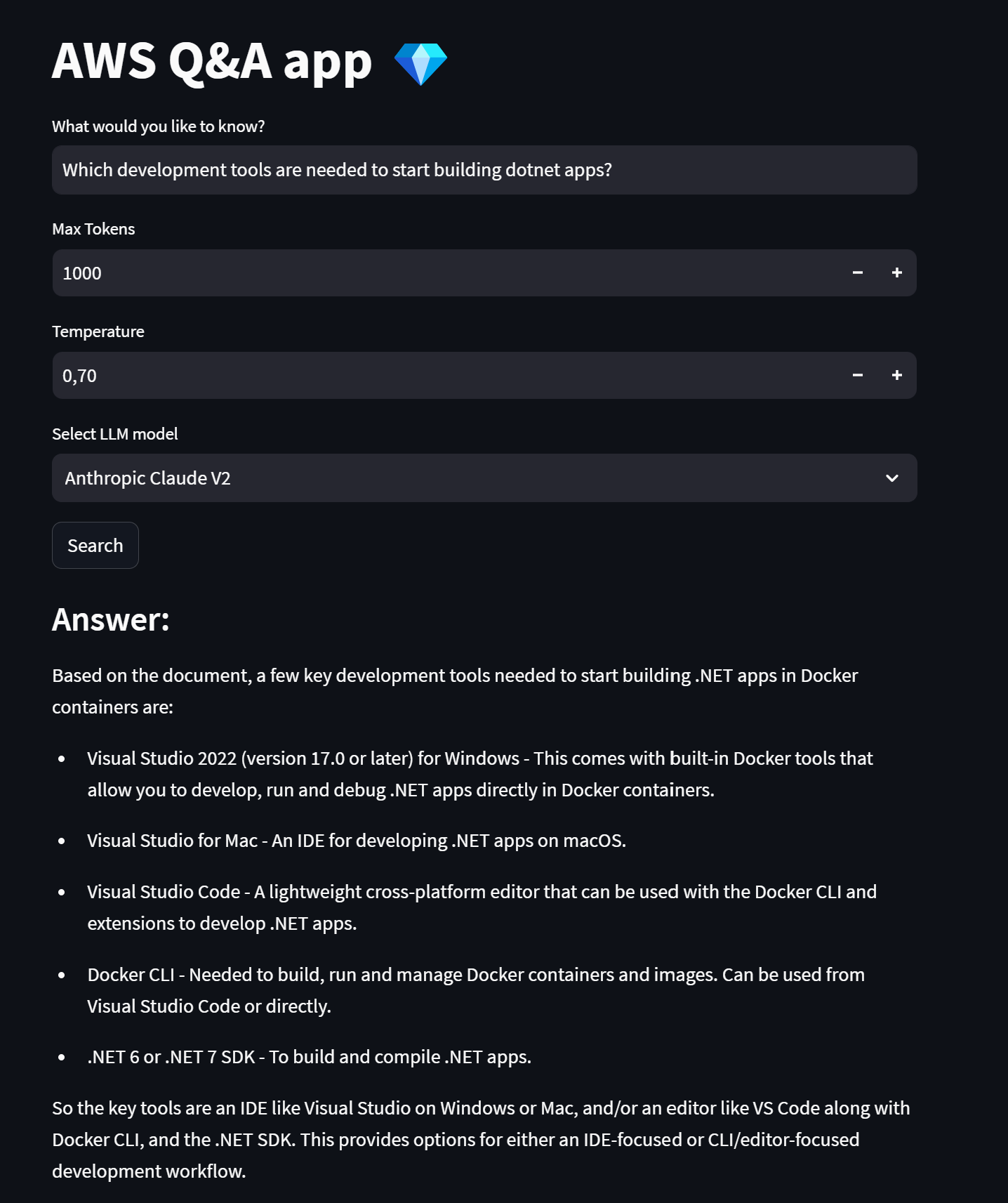
The next image showcases how the user interface will look once it is fully built.
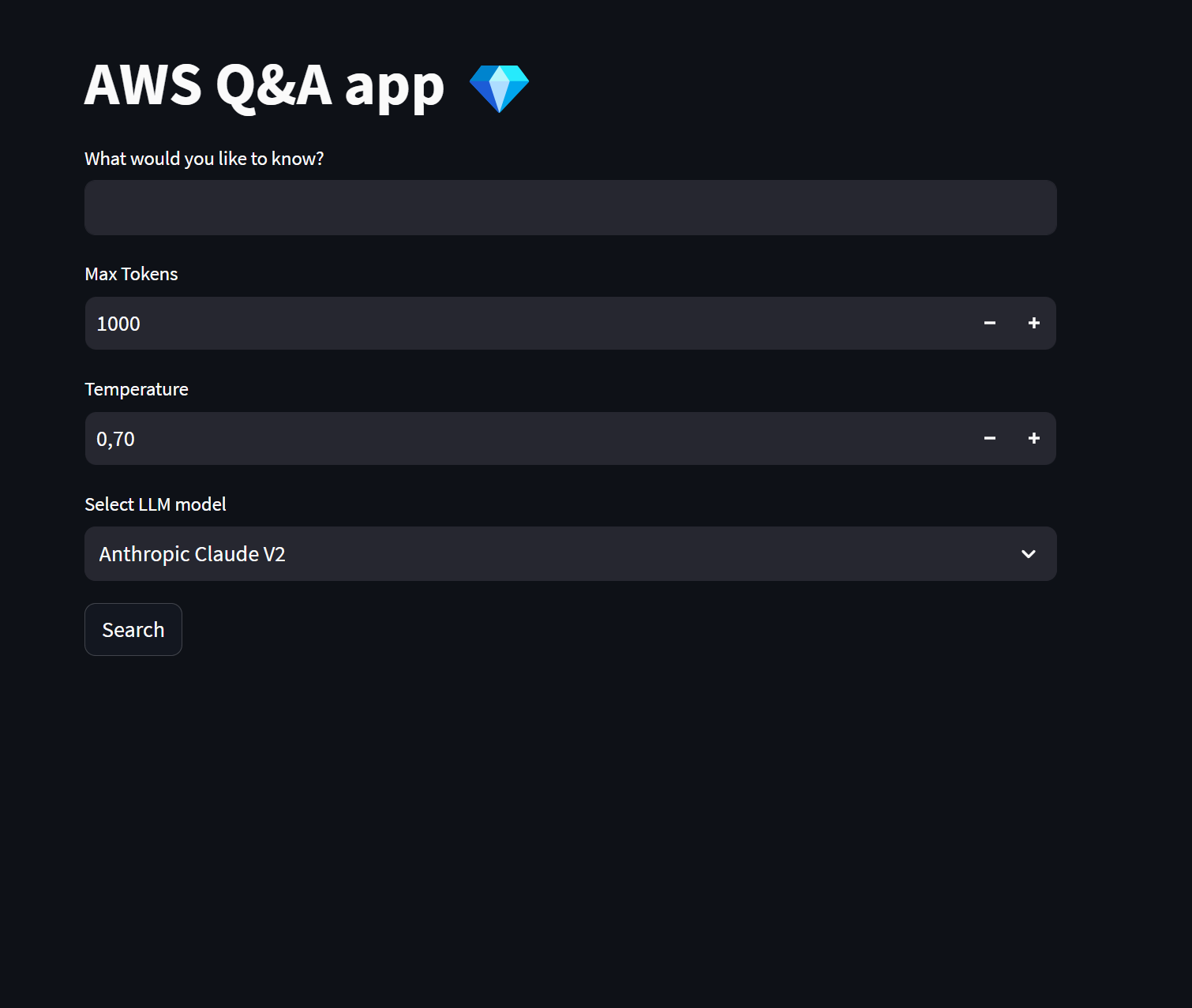
Once a user types a question in the text input, selects which AWS Bedrock LLM wants to use, and presses the submit button, the following steps will be executed:
- Run the user query on AWS Kendra and retrieve the relevant information.
- Assemble a prompt.
- Send the prompt to one of the AWS Bedrock LLMs and get the answer that comes back.
In this first version of Q&A app we will make heavy use of the LangChain library to build the RAG pattern and to interact with AWS Kendra and AWS Bedrock.
LangChain works great when building a RAG pattern that involves AWS Kendra and AWS Bedrock. With LangChain, we can retrieve the relevant documents related to our query from Kendra with just a single line of code and build an entire RAG workflow using one of the already pre-built “chains” that LangChain offers.
Now, let’s take a look at the source code and then I’ll try to explain the most relevant parts.
from langchain.retrievers import AmazonKendraRetriever
from langchain.llms.bedrock import Bedrock
from langchain.chains import RetrievalQA
from dotenv import load_dotenv
import streamlit as st
import os
import boto3
load_dotenv()
if os.getenv('KENDRA_INDEX') is None:
st.error("KENDRA_INDEX not set. Please set this environment variable and restart the app.")
if os.getenv('AWS_BEDROCK_REGION') is None:
st.error("AWS_BEDROCK_REGION not set. Please set this environment variable and restart the app.")
if os.getenv('AWS_KENDRA_REGION') is None:
st.error("AWS_KENDRA_REGION not set. Please set this environment variable and restart the app.")
kendra_index = os.getenv('KENDRA_INDEX')
bedrock_region = os.getenv('AWS_BEDROCK_REGION')
kendra_region = os.getenv('AWS_KENDRA_REGION')
def get_kendra_doc_retriever():
kendra_client = boto3.client("kendra", kendra_region)
retriever = AmazonKendraRetriever(index_id=kendra_index, top_k=3, client=kendra_client, attribute_filter={
'EqualsTo': {
'Key': '_language_code',
'Value': {'StringValue': 'en'}
}
})
return retriever
st.title("AWS Q&A app 💎")
query = st.text_input("What would you like to know?")
max_tokens = st.number_input('Max Tokens', value=1000)
temperature= st.number_input(label="Temperature",step=.1,format="%.2f", value=0.7)
llm_model = st.selectbox("Select LLM", ["Anthropic Claude V2", "Amazon Titan Text Express v1", "Ai21 Labs Jurassic-2 Ultra"])
if st.button("Search"):
with st.spinner("Building response..."):
if llm_model == 'Anthropic Claude V2':
retriever = get_kendra_doc_retriever()
bedrock_client = boto3.client("bedrock-runtime", bedrock_region)
llm = Bedrock(model_id="anthropic.claude-v2", region_name=bedrock_region,
client=bedrock_client,
model_kwargs={"max_tokens_to_sample": max_tokens, "temperature": temperature})
qa = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=retriever)
response = qa(query)
st.markdown("### Answer:")
st.write(response['result'])
if llm_model == 'Amazon Titan Text Express v1':
retriever = get_kendra_doc_retriever()
bedrock_client = boto3.client("bedrock-runtime", bedrock_region)
llm = Bedrock(model_id="amazon.titan-text-express-v1", region_name=bedrock_region,
client=bedrock_client,
model_kwargs={"maxTokenCount": max_tokens, "temperature": temperature})
qa = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=retriever)
response = qa(query)
st.markdown("### Answer:")
st.write(response['result'])
if llm_model == 'Ai21 Labs Jurassic-2 Ultra':
retriever = get_kendra_doc_retriever()
bedrock_client = boto3.client("bedrock-runtime", bedrock_region)
llm = Bedrock(model_id="ai21.j2-ultra-v1", region_name=bedrock_region,
client=bedrock_client,
model_kwargs={"maxTokens": max_tokens, "temperature": temperature})
qa = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=retriever)
response = qa(query)
st.markdown("### Answer:")
st.write(response['result'])
There isn’t much to comment on here since the code is quite straightforward. Nonetheless, let’s take a closer look and provide a step-by-step explanation of what each line of code is accomplishing.
3.1. Get user parameters from the User Interface
The first step is to simply retrieve the user parameters from the UI:
- User query.
- LLM max tokens limit.
- LLM temperature.
- Which AWS Bedrock LLM does the user want to use.
query = st.text_input("What would you like to know?")
max_tokens = st.number_input('Max Tokens', value=1000)
temperature= st.number_input(label="Temperature",step=.1,format="%.2f", value=0.7)
llm_model = st.selectbox("Select LLM", ["Anthropic Claude V2", "Amazon Titan Text Express v1", "Ai21 Labs Jurassic-2 Ultra"])
3.2. Define how we’re going to retrieve the relevant information from Kendra
To retrieve the relevant docs from our knowledge database (AWS Kendra), we’re going to use the LangChainAmazonKendraRetriever class.
The AmazonKendraRetriever class uses Amazon Kendra’s Retrieve API to make queries to the Amazon Kendra index and obtain the docs that are most relevant to the user query.
The AmazonKendraRetriever class will be plugged into a LangChain chain to build the RAG pattern.
An important thing to understand here is that we’re not retrieving the docs from Kendra right now; we’re only declaring a way to retrieve them. It will be the LangChain chain who uses the AmazonKendraRetriever class to obtain the relevant documents. (More on section 4.4).
The LangChain AmazonKendraRetrieves class creates a Kendra boto3 client by default, but if you want to customize the configuration, it is better to explicitly create the client beforehand, and pass it to the Langchain class.
The top_k parameter is used to specify how many documents we want to retrieve from Kendra, for this example we’re retrieving the top 3 docs that are most similar to our question.
Why did we retrieve 3 docs from our knowledge database instead of just one?
When we saved the documents, data is stored into multiple chunks, so it’s possible that the complete answer to our question is not located in just one vector but in more than one. That’s why we’re retrieving the 3 most relevant documents to the given question.
def get_kendra_doc_retriever():
kendra_client = boto3.client("kendra", kendra_region)
retriever = AmazonKendraRetriever(index_id=kendra_index, top_k=3, client=kendra_client, attribute_filter={
'EqualsTo': {
'Key': '_language_code',
'Value': {'StringValue': 'en'}
}
})
return retriever
3.3. Initialize the LangChain Bedrock client
To interact with AWS Bedrock LLMs, we’re going to use the LangChain Bedrock class.
The LangChain Bedrock class allow us to setup the Bedrock LLM we want to use. In this specific code snippet, we’re setting up the Amazon Titan Text Express v1 LLM.
This Bedrock class will be plugged into a LangChain chain to build the RAG pattern. (More on section 4.4).
The LangChain Bedrock class creates a Bedrock boto3 client by default, but if you want to customize the configuration, it is better to explicitly create the Bedrock client beforehand, and pass it to the Langchain.
bedrock_client = boto3.client("bedrock-runtime", bedrock_region)
llm = Bedrock(model_id="amazon.titan-text-express-v1", region_name=bedrock_region,
client=bedrock_client,
model_kwargs={"maxTokenCount": max_tokens, "temperature": temperature})
3.4. Create a LangChain RetrievalQA chain
- In section 4.2, we declared a way to retrieve the documents from our knowledge database using the
AmazonKendraRetrieverimplementation. - In section 4.3, we declared a way to interact with a Bedrock LLM using the
Bedrockclass.
Now, what we need to do to build a RAG workflow? Just a LangChain “chain”.
The RetrievalQA chain is the key component for building the RAG pattern. This LangChain chain handles everything for you under the hood:
- Uses the
AmazonKendraRetrieverimplementation to retrieve the most relevant docs from Kendra - Creates the prompt and attaches the data obtained from Kendra.
- Sends the prompt to an AWS Bedrock LLM and gets the answer that comes back.
qa = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=retriever)
response = qa(query)
st.markdown("### Answer:")
st.write(response['result'])
And that’s it! You have a functional RAG workflow that uses AWS Kendra and AWS Bedrock and it is no more than 10 - 15 lines of code, and all thanks to LangChain.
4. Build the Q&A app using boto3 (and without using LangChain)
In this section we’re going to build the same Q&A app from the previous section (section 4), but this time without making use of the
LangChainlibrary.
The Streamlit app we have built in the previous section makes heavy use of the LangChain library to implement the RAG pattern.
But what if you prefer not to use any third-party libraries and set up the RAG pattern using only the AWS SDK for Python library?
It is true that LangChain handles part of the heavy work for you under the covers, but implementing the RAG pattern using only the boto3 library is not difficult at all.
Let’s get to it. First, let’s take a look at the end result and then I’ll explain the most relevant parts again.
from dotenv import load_dotenv
import streamlit as st
import os
import boto3
import json
load_dotenv()
if os.getenv('KENDRA_INDEX') is None:
st.error("KENDRA_INDEX not set. Please set this environment variable and restart the app.")
if os.getenv('AWS_BEDROCK_REGION') is None:
st.error("AWS_BEDROCK_REGION not set. Please set this environment variable and restart the app.")
if os.getenv('AWS_KENDRA_REGION') is None:
st.error("AWS_KENDRA_REGION not set. Please set this environment variable and restart the app.")
kendra_index = os.getenv('KENDRA_INDEX')
bedrock_region = os.getenv('AWS_BEDROCK_REGION')
kendra_region = os.getenv('AWS_KENDRA_REGION')
def retrieve_kendra_docs():
kendra_client = boto3.client("kendra", kendra_region)
result = kendra_client.retrieve(QueryText = query,
IndexId = kendra_index,
PageSize = 3,
PageNumber = 1)
chunks = [retrieve_result["Content"] for retrieve_result in result["ResultItems"]]
joined_chunks = "\n".join(chunks)
return joined_chunks
def build_prompt(query, docs):
prompt = f"""Human: You're a QA assistant.
Answer the following question based on the context below.
If you don't know the answer, just say that you don't know. Don't try to make up an answer. Do not answer beyond this context.
---
QUESTION: {query}
---
CONTEXT:
{docs}
Assistant:"""
return prompt
st.title("AWS Q&A app 💎")
query = st.text_input("What would you like to know?")
max_tokens = st.number_input('Max Tokens', value=1000)
temperature= st.number_input(label="Temperature",step=.1,format="%.2f", value=0.7)
llm_model = st.selectbox("Select LLM", ["Anthropic Claude V2", "Amazon Titan Text Express v1", "Ai21 Labs Jurassic-2 Ultra"])
if st.button("Search"):
with st.spinner("Building response..."):
if llm_model == 'Anthropic Claude V2':
docs = retrieve_kendra_docs()
prompt = build_prompt(query, docs)
body = json.dumps({
"prompt": prompt,
"max_tokens_to_sample": max_tokens,
"temperature": temperature
})
bedrock_client = boto3.client("bedrock-runtime", bedrock_region)
response = bedrock_client.invoke_model(
body=body,
modelId='anthropic.claude-v2'
)
response = json.loads(response.get("body").read())
st.markdown("### Answer:")
st.write(response.get("completion"))
if llm_model == 'Amazon Titan Text Express v1':
docs = retrieve_kendra_docs()
prompt = build_prompt(query, docs)
bedrock_client = boto3.client("bedrock-runtime", bedrock_region)
body = json.dumps({
"inputText": prompt,
"textGenerationConfig":{
"maxTokenCount":max_tokens,
"temperature":temperature,
}
})
response = bedrock_client.invoke_model(
body=body,
modelId='amazon.titan-text-express-v1'
)
result = json.loads(response.get('body').read())
st.markdown("### Answer:")
st.write(result.get('results')[0].get('outputText'))
if llm_model == 'Ai21 Labs Jurassic-2 Ultra':
docs = retrieve_kendra_docs()
prompt = build_prompt(query, docs)
bedrock_client = boto3.client("bedrock-runtime", bedrock_region)
body = json.dumps({
"prompt": prompt,
"maxTokens": max_tokens,
"temperature": temperature
})
response = bedrock_client.invoke_model(
body=body,
modelId='ai21.j2-ultra-v1'
)
result = json.loads(response.get("body").read())
st.markdown("### Answer:")
st.write(result.get("completions")[0].get("data").get("text"))
4.1. Get user parameters from the User Interface
The first step is to simply retrieve the user parameters from the UI:
- User query.
- LLM max tokens limit.
- LLM temperature.
- Which AWS Bedrock LLM does the user want to use.
query = st.text_input("What would you like to know?")
max_tokens = st.number_input('Max Tokens', value=1000)
temperature= st.number_input(label="Temperature",step=.1,format="%.2f", value=0.7)
llm_model = st.selectbox("Select LLM", ["Anthropic Claude V2", "Amazon Titan Text Express v1", "Ai21 Labs Jurassic-2 Ultra"])
4.2. Retrieve the relevant information from Kendra
The retrieve method from the boto3 Kendra client allow us to retrieve the relevant docs from our knowledge database.
The PageSize parameter is used to specify how many documents we want to retrieve, for this example we’re retrieving the top 3 docs that are most similar to our question.
Why did we retrieve 3 docs from our knowledge database instead of just one?
When we saved the documents, data is stored into multiple chunks, so it’s possible that the complete answer to our question is not located in just one vector but in more than one. That’s why we’re retrieving the 3 most relevant documents to the given question.
Once we have retrieved the documents from Kendra, we merge them into a single “string”.
This “string” represents the context that will be added to the prompt, specifying to the Bedrock LLM that it can only respond using the information provided in this context. It cannot use any data from outside this context to generate the answer to our question.
def retrieve_kendra_docs():
kendra_client = boto3.client("kendra", kendra_region)
result = kendra_client.retrieve(QueryText = query,
IndexId = kendra_index,
PageSize = 3,
PageNumber = 1)
chunks = [retrieve_result["Content"] for retrieve_result in result["ResultItems"]]
joined_chunks = "\n".join(chunks)
return joined_chunks
4.3. Assemble the prompt
Now, we construct the prompt that we will be sending to a Bedrock LLM.
Within the prompt, you will notice the placeholders {query} and {docs}.
- The
{query}placeholder is where the app will add the user query. - The
{docs}placeholder is where the app will add the context retrieved from Kendra.
def build_prompt(query, docs):
prompt = f"""Human: You're a QA assistant.
Answer the following question based on the context below.
If you don't know the answer, just say that you don't know. Don't try to make up an answer. Do not answer beyond this context.
---
QUESTION: {query}
---
CONTEXT:
{docs}
Assistant:"""
return prompt
4.4. Send the prompt to a Bedrock LLM and get the answer that comes back
The last step is sending the prompt to one of the Bedrock LLMs using the invoke_model method from the boto3 Bedrock client, and get the answer that comes back.
bedrock_client = boto3.client("bedrock-runtime", bedrock_region)
body = json.dumps({
"inputText": prompt,
"textGenerationConfig":{
"maxTokenCount":max_tokens,
"temperature":temperature,
}
})
response = bedrock_client.invoke_model(
body=body,
modelId='amazon.titan-text-express-v1'
)
result = json.loads(response.get('body').read())
st.markdown("### Answer:")
st.write(result.get('results')[0].get('outputText'))
And that’s it! You have successfully built a RAG workflow using AWS Bedrock, AWS Kendra, and the AWS SDK for Python.
Testing the Q&A app
Let’s test if the Q&A app works correctly.
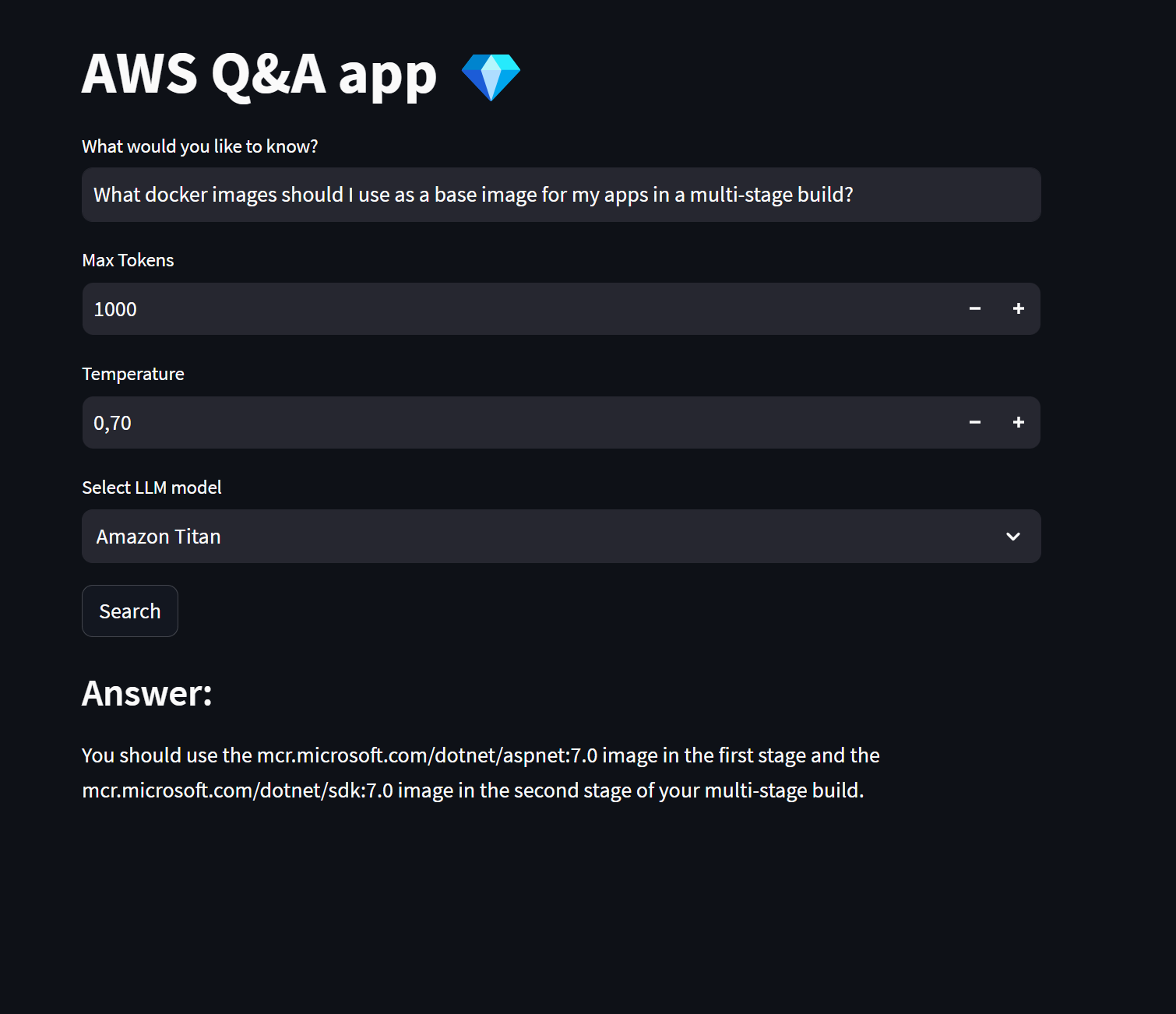
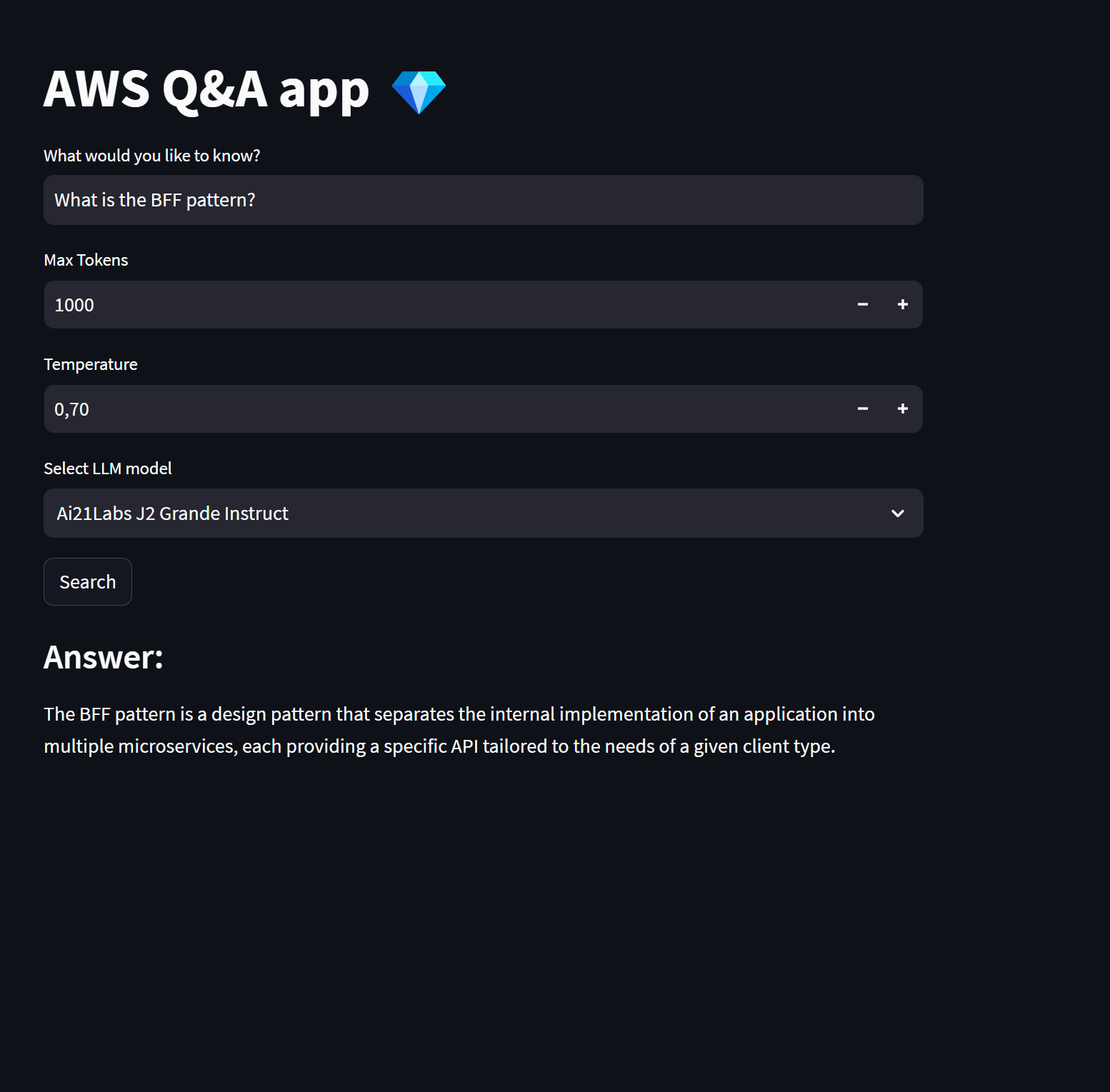
Remember that the document we used to fill the knowledge base is the Microsoft .NET Microservices book, so all questions we ask should be about that specific topic.
- Question 1:

- Question 2:
- Question 3:
- Question 4: