Building a serverless API that tweets about my blog posts using Azure OpenAI and LangChain
Just show me the code!
As always, if you don’t care about the post I have uploaded the source code on my Github.
The other day I thought that maybe I should start promoting in Twitter my blog posts, a good starting point would be to create a new tweet with a brief summary every time a new post gets published in my blog.
The truth is that I’m not a big fan of Twitter and I don’t want to have to manually write tweets, so I’ve thought about automating the creation of these tweets in some way.
The hottest topic right now is undoubtedly ChatGPT and Large Language Models (LLM), so I thought, “What if I let ChatGPT write these tweets recommending my posts for me?”.
In the end, I’ve come to the conclusion that I’m going to build an API that takes one of my post’s URLs as a parameter and is responsible for:
- Retrieving the text from my post.
- Calling ChatGPT to draft a tweet summarizing the content of my post.
- Posting it on Twitter.
In this post, I’m going to focus on setting up this API, so if you’re interested, keep reading.
Application to build
This API is only going to be used when a new post is published, so it doesn’t make sense to continuously host it on services like App Services. For this use case, the best option is to go serverless and use a service like Azure Functions.
Instead of using ChatGPT, I’m going to use its Microsoft counterpart: Azure OpenAI. Right now, this service is in preview, so in order to use it, you need to fill out a form and wait for Microsoft to grant you access.
I’m going to develop the API using Python and to communicate with OpenAI, I’ll be using the LangChain library.
What is LangChain?
At its core, LangChain is a framework built around LLMs. It provides a simple and intuitive interface to interact with LLM models.
LangChain provides a set of abstractions that handle all the necessary steps for interacting with the LLM model, including authentication, input preprocessing, and result post-processing. With LangChain, you can quickly generate natural language text that is tailored to your specific needs.
LangChain also provides a set of implementations for the most well-known LLM interaction strategies.
The core idea of the library is that we can chain together different components to create more advanced use cases around LLMs. Chains may consist of multiple components from several modules:
- Prompt templates: Prompt templates are templates for different types of prompts.
- LLMs: Large language models like GPT-3, BLOOM, etc
- Agents: Agents use LLMs to decide what actions should be taken.
- Memory: Short-term memory, long-term memory.
If you want to know more about it, visit its site:
How the app works
The following diagram shows how the API is going to work:

The principle is really simple:
- The API must be called with a parameter called
uriin the Http request body, here’s an example:
curl -X POST https://func-openai-azfunc-dev.azurewebsites.net/api/tweet?code=hoZ6u8lIMlhu7-Zs8gvDb04R2fXvYeapijR3YYRlgiwmAzFulsiRMA== \
-H "Content-Type: application/json" \
-d '{"uri": "https://www.mytechramblings.com/posts/deploy-az-resources-when-not-available-on-azurerm/"}'
The parameter uri indicates the website from where to obtain the content that will get summarized.
- The API fetches the content from the
uriwebsite. - The text content is split into multiple chunks. The reason to split it into multiple parts is that the text might be too long to be summarized by a single request to Azure OpenAI.
- Every chunk gets summarized independently using Azure OpenAI.
- All the summarized chunks are put together in a single piece of text and summarized again with Azure OpenAI. The resulting text is the tweet.
- The tweet gets posted to Twitter.
Building the tweeting API
Let me show you the final result, and from there, I’ll explain to you line by line what the API is doing.
import azure.functions as func
import os
import tweepy
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.document_loaders import UnstructuredURLLoader
from langchain.chains.summarize import load_summarize_chain
from langchain.chat_models import AzureChatOpenAI
from langchain.prompts import PromptTemplate
prompt_template = """
You are the author of the source text.
You need to write a tweet that summarizes the source text.
The tweet must not contain any kind of code.
Make sure the tweet is compelling and well-written.
The tweet must end with the following phrase: 'More details in: www.mytechramblings.com'
The total tweet size must have no more than 270 characters.
SOURCE:
{text}
TWEET IN ENGLISH:"""
app = func.FunctionApp()
@app.function_name(name="TweetApi")
@app.route(route="tweet")
def test_function(req: func.HttpRequest) -> func.HttpResponse:
try:
# Get twitter credentials
twitter_consumer_key = os.environ['TWITTER_CONSUMER_KEY']
twitter_consumer_secret = os.environ['TWITTER_CONSUMER_SECRET']
twitter_access_token = os.environ['TWITTER_ACCESS_TOKEN']
twitter_access_token_secret = os.environ['TWITTER_ACCESS_TOKEN_SECRET']
# Get Azure OpenAi credentials
az_open_ai_url = os.environ['OPENAI_URL']
az_open_ai_apikey = os.environ['OPENAI_APIKEY']
az_open_ai_deployment_name = os.environ['OPENAI_DEPLOYMENT_NAME']
except KeyError:
return func.HttpResponse("Something went wrong when trying to retrieve the credentials", status_code=500)
try:
# Read uri from HTTP request
req_body = req.get_json()
uri = req_body.get('uri')
except ValueError:
return func.HttpResponse( "The request has a missing body.", status_code=400)
if not uri:
return func.HttpResponse( "The 'uri' attribute is missing in the request body.", status_code=400)
else:
try:
# Create Azure OpenAI client
llm = AzureChatOpenAI(
openai_api_base=az_open_ai_url,
openai_api_version="2023-03-15-preview",
deployment_name=az_open_ai_deployment_name,
openai_api_key=az_open_ai_apikey,
openai_api_type = "azure",
)
# Read context from URI
loader = UnstructuredURLLoader(urls=[uri])
data = loader.load()
# Split content into chunks
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=20)
texts = text_splitter.split_documents(data)
# Run langchain 'map_reduce' chain
prompt = PromptTemplate(template=prompt_template, input_variables=["text"])
chain = load_summarize_chain(llm, chain_type="map_reduce", combine_prompt=prompt)
output = chain.run(texts)
# Print tweet content
print(output)
# Create Twitter client
client = tweepy.Client(
consumer_key=twitter_consumer_key, consumer_secret=twitter_consumer_secret,
access_token=twitter_access_token, access_token_secret=twitter_access_token_secret
)
# Create tweet using langchain 'map_reduce' chain output
response = client.create_tweet(
text=output
)
return func.HttpResponse(f"https://twitter.com/user/status/{response.data['id']}")
except tweepy.TweepyException as e:
return func.HttpResponse(f"Something went wrong when creating the tweet: {e}", status_code=500)
except Exception as ex:
return func.HttpResponse(f"Something went wrong: {ex}", status_code=500)
As you can see, the implementation is no more than 50 lines of Python, which is largely thanks to the LangChain library, as it implements some of the most well-known patterns for interacting with an LLM model, this allows us to implement the map-reduce strategy with just a couples lines of code.
But before we start talking about the map-reduce strategy, let’s review each line of the API and explain what I’m doing.
1. Set Azure OpenAI & Twitter credentials
A series of credentials are required to communicate with Azure OpenAI and the Twitter API. In the following code block, we are simply obtaining these credentials from configuration.
TWITTER_CONSUMER_KEY: Twitter API consumer key.TWITTER_CONSUMER_SECRET: Twitter API consumer secret.TWITTER_ACCESS_TOKEN: Twitter API access token.TWITTER_ACCESS_TOKEN_SECRET: Twitter API access token secret.OPENAI_URL: The URL of your Azure OpenAI service.- It has the following format:
https://{base}.openai.azure.com
- It has the following format:
OPENAI_DEPLOYMENT_NAME: The Azure OpenAI model deployment name.OPENAI_APIKEY: The Azure OpenAI api key.
try:
# Get twitter credentials
twitter_consumer_key = os.environ['TWITTER_CONSUMER_KEY']
twitter_consumer_secret = os.environ['TWITTER_CONSUMER_SECRET']
twitter_access_token = os.environ['TWITTER_ACCESS_TOKEN']
twitter_access_token_secret = os.environ['TWITTER_ACCESS_TOKEN_SECRET']
# Get Azure OpenAi credentials
az_open_ai_url = os.environ['OPENAI_URL']
az_open_ai_apikey = os.environ['OPENAI_APIKEY']
az_open_ai_deployment_name = os.environ['OPENAI_DEPLOYMENT_NAME']
except KeyError:
return func.HttpResponse("Something went wrong when trying to retrieve the credentials", status_code=500)
2. Get the ‘uri’ property from the HTTP body request
The API will be called with a parameter called uri in the Http request body, here’s an example:
curl -X POST https://func-openai-azfunc-dev.azurewebsites.net/api/tweet?code=hoZ6u8lIMlhu7-Zs8gvDb04R2fXvYeapijR3YYRlgiwmAzFulsiRMA== \
-H "Content-Type: application/json" \
-d '{"uri": "https://www.mytechramblings.com/posts/deploy-az-resources-when-not-available-on-azurerm/"}'
This uri parameter will indicate the website URL from where to obtain the content that will get summarized.
In the following code block, we are obtaining the uri property from the Http request body. If it doesn’t exist, the API responds with a 400 status code.
try:
# Read uri from HTTP request
req_body = req.get_json()
uri = req_body.get('uri')
except ValueError:
return func.HttpResponse( "The request has a missing body.", status_code=400)
if not uri:
return func.HttpResponse( "The 'uri' attribute is missing in the request body.", status_code=400)
3. Read and split the blog post content
Once we know the URL from which we need to read the content, we use the Langchain UnstructuredURLLoader functionality to obtain it.
The UnstructuredURLLoader uses the Unstructured python package under the hood. This package is a great way to transform all types of files - text, powerpoint, images, html, pdf, etc - into text data.
Apart from reading the content, in the following code block we’re setting up the AzureChatOpenAi class, this class will be used in the next section.
The AzureChatOpenAi class allows us to communicate with the desired LLM model from those available in Azure OpenAI. In our case, we are using a gpt-3.5-turbo model, since as of today, I still do not have access to the gpt-4 model.
# Create Azure OpenAI client
llm = AzureChatOpenAI(
openai_api_base=az_open_ai_url,
openai_api_version="2023-03-15-preview",
deployment_name=az_open_ai_deployment_name,
openai_api_key=az_open_ai_apikey,
openai_api_type = "azure",
)
# Read context from URI
loader = UnstructuredURLLoader(urls=[uri])
data = loader.load()
4. Create the tweet content using a ‘map-reduce’ strategy and a custom prompt template
LLMs have a limited token length, which means we cannot pass it an entire wall of text at once to summarize, we need a more clever technique to decompose it, this is where the map-reduce strategy comes into play.
The map-reduce strategy is one of the multiple strategies available today for interacting with LLM models. It consists in:
- Splitting a text into multiples chunks of data.
- To split the text into multiple chunks, we will use the Langchain
RecursiveCharacterTextSplitterfunctionality.
- To split the text into multiple chunks, we will use the Langchain
- Pass every chunk of data through the language model to generate multiple responses.
- Combine the multiple responses into a single one and then pass it again through the language model to obtain a definitive response.
As you can imagine, this technique requires more than one call to the LLM/Azure OpenAI.
The next diagram shows the map-reduce strategy that we’re going to implement:
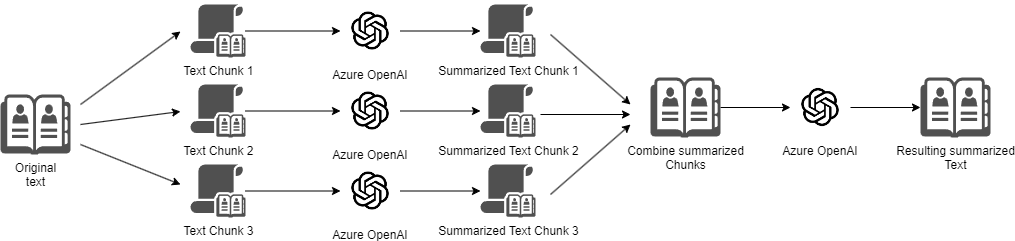
The map-reduce strategy might seem quite complex to implement, but LangChain provides a set of implementations for the most well-known LLM interaction strategies, which means that implementing the map-reduce strategy with LangChain becomes a simple one-liner:
from langchain.chains.summarize import load_summarize_chain
...
load_summarize_chain(llm, chain_type="map_reduce")
In the following code block, we’re spliting the text into multiple chunks using the Langchain RecursiveCharacterTextSplitter functionality, and then we apply the map-reduce strategy using the load_summarize_chain function. The end result is the tweet that is going to be posted to Twitter.
# Split content into chunks
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=20)
texts = text_splitter.split_documents(data)
# Run langchain 'map_reduce' chain
prompt = PromptTemplate(template=prompt_template, input_variables=["text"])
chain = load_summarize_chain(llm, chain_type="map_reduce", combine_prompt=prompt)
output = chain.run(texts)
Langchain applies a default prompt every time it sends text to the LLM model. In our case, we want to modify the combine prompt that is sent to the LLM model to fit Twitter’s constraints.
We can use the combine_prompt parameter from the load_summarize_chain function to set the prompt that is going to be sent when trying to summarize the compacted chunks.
We can also customize the prompts used to generate the summary of every single chunk using the map_prompt parameter, but I don’t need it, the default summarization prompt is good enough.
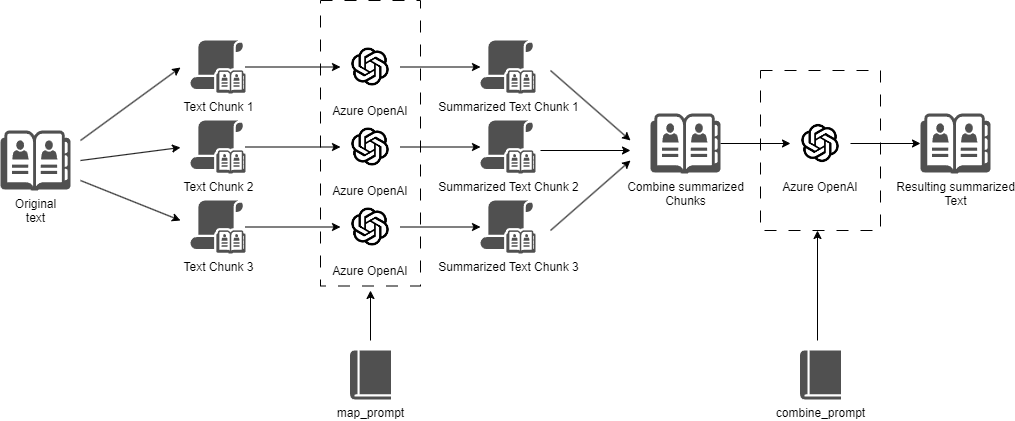
After some prompt engineering and some trial and error, here’s how the combine prompt ended up looking like:
prompt_template = """
You are the author of the source text.
You need to write a tweet that summarizes the source text.
The tweet must not contain any kind of code.
Make sure the tweet is compelling and well-written.
The tweet must end with the following phrase: 'More details in: www.mytechramblings.com'
The total tweet size must have no more than 270 characters.
SOURCE:
{text}
TWEET IN ENGLISH:"""
LangChain will combine the multiple summarized chunks into a single text and replace the {text} placeholder with it, and afterwards it will sent the resulting prompt to Azure OpenAI to generate the tweet.
5. Post the new tweet using the Twitter Api
Once we have the tweet we are going to create, we can use the Python library tweepy to create it.
In the following code block, we are posting the new tweet to Twitter using tweepy and returning the tweet URI to the client. As you can see, the code is descriptive enough.
# Create Twitter client
client = tweepy.Client(
consumer_key=twitter_consumer_key, consumer_secret=twitter_consumer_secret,
access_token=twitter_access_token, access_token_secret=twitter_access_token_secret
)
# Create tweet using langchain 'map_reduce' chain output
response = client.create_tweet(
text=output
)
return func.HttpResponse(f"https://twitter.com/user/status/{response.data['id']}")
Testing the API
The next step after building the API is to test that it works correctly. For this purpose, I have created a new temporary Twitter account specifically for this.
To invoke the API, you can use any tool capable of making an HTTP request (cURL, Postman, Insomnia, etc.), you just have to make an HTTP call to the /tweet endpoint of the API.
Here’s an example using cURL to call the API running in Azure:
curl -X POST https://func-openai-azfunc-dev.azurewebsites.net/api/tweet?code=hoZ6u8lIMlhu7-Zs8gvDb04R2fXvYeapijR3YYRlgiwmAzFulsiRMA== \
-H "Content-Type: application/json" \
-d '{"uri": "https://www.mytechramblings.com/posts/deploy-az-resources-when-not-available-on-azurerm/"}'
And here’s another example using cURL to call the API running locally:
curl -X POST http://localhost:7071/api/tweet \
-H "Content-Type: application/json" \
-d '{"uri": "https://www.mytechramblings.com/posts/how-to-integrate-your-roslyn-analyzers-with-sonarqube"}'
It takes around 40 to 50 seconds to create the tweet and post it to Twitter. Here’s how the end result looks like in Twitter.
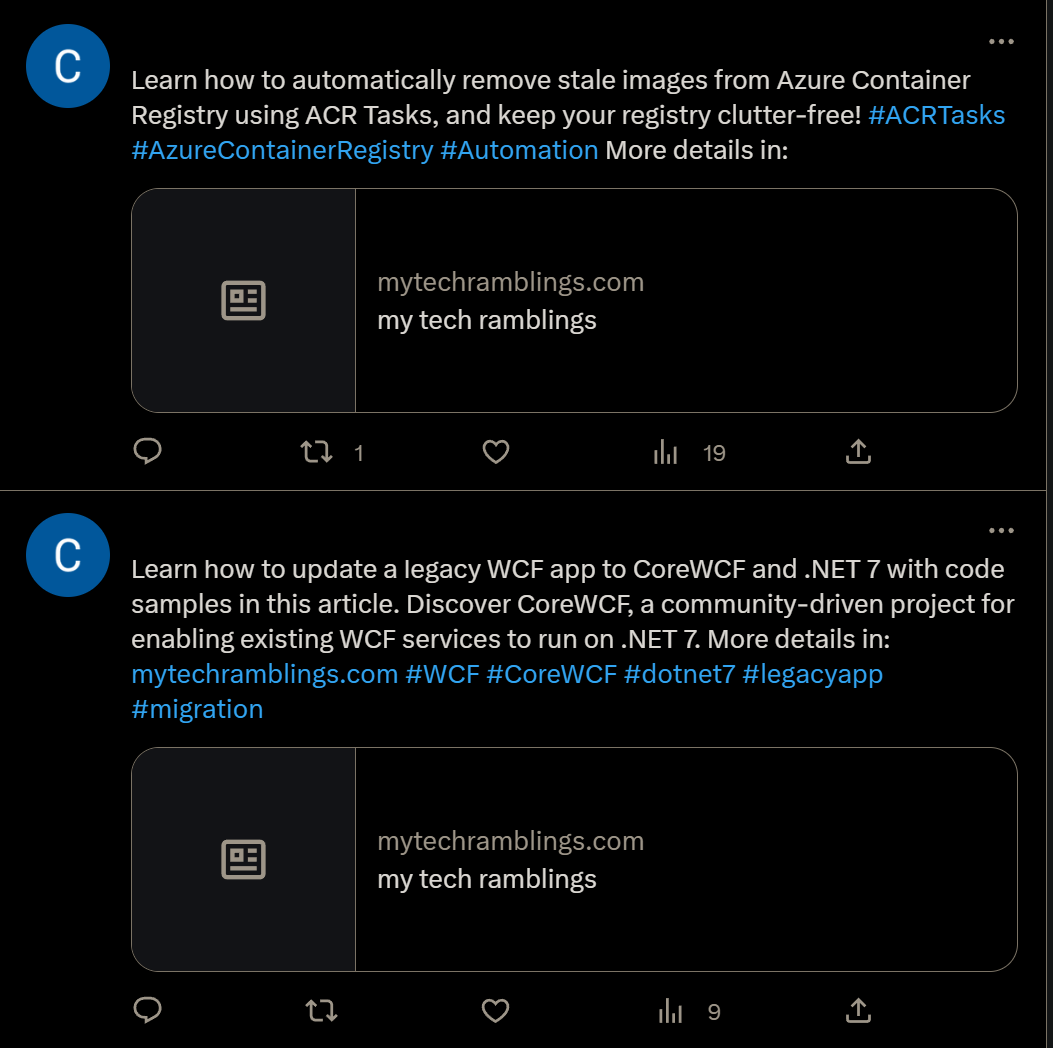
And a few more tweets:
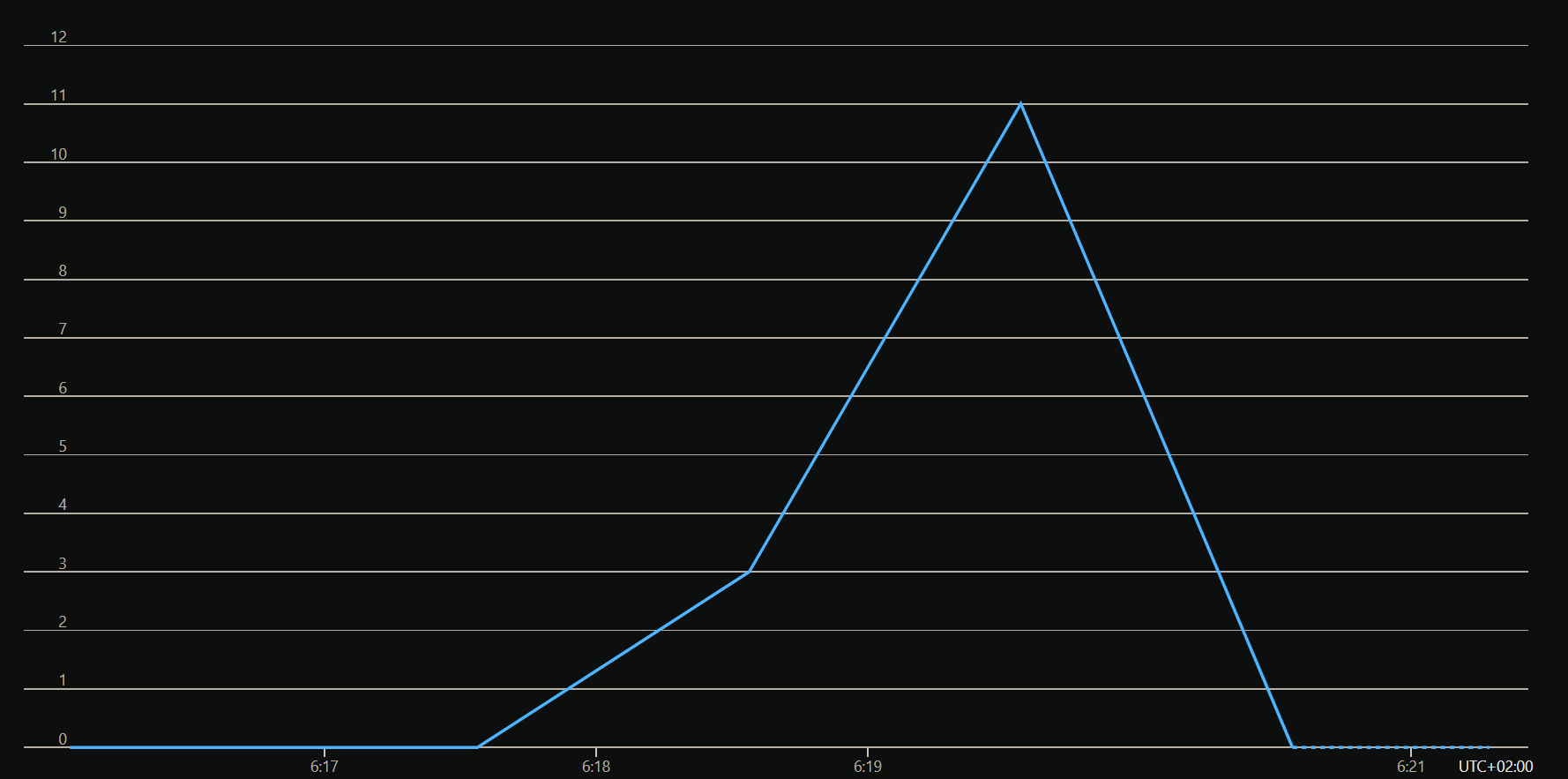
Do you remember when in the previous section we talked about the map-reduce strategy making multiple calls to the LLM model?
If we look at the metrics of the total calls made to Azure OpenAI to generate a single tweet, we can clearly see it.
The following image shows a total of 12 calls made to Azure OpenAI to generate a single tweet