Provisioning resources on AWS using AWS CDK and Azure DevOps Pipelines
Introduction
First of all let me tell you that I’m huge proponent of Terraform as a framework for defining infrastructure in code.
One of the things that I like most about Terraform is that not only every major cloud provider (AWS, Azure, GCP) offers their own provider but each day more and more companies are starting to offer their own Terraform providers, and those are great news because with Terraform I can create almost any cloud infrastructure that I want and also a huge array of varied resources such as: VMware vSphere Virtual Machines, RabbitMq Queues, Grafana dashboards amongst many many others.
And let’s not forget that building your own Terraform provider it’s quite easy, so if you need to create some resources using Terraform but the provider does not exist you can always built it yourself.
Anyways, this post is starting to sound like a sales pitch for Terraform… So let’s stop talking about Terraform and let’s make some focus on AWS CDK.
What’s AWS CDK? AWS CDK is another software development framework for defining cloud infrastructure in code.
One of the main differences is that it uses AWS CloudFormation for provisioning the resources, in fact we could say that AWS CDK is nothing more than a developing framework built on top of Cloudformation. That means that AWS CDK is a development framework for manage “only” AWS infrastructure.
And why should we care about AWS CDK?
Well if you’re not a multi-cloud / hybrid-cloud enterprise and you’re staying entirely within AWS, then AWS CDK is hands-down a much better option than Terraform. In my opinion Terraform thrives as a “jack-of-all trades” IaC tool, meanwhile AWS CDK has been built to work specifically with AWS and what it does, it does it right.
And why use AWS CDK instead of Cloudformation?
With AWS CDK you can do the same things you do with Cfn but with much less code and much more quickly.
Also one of the coolest things about AWS CDK is that like Pulumi it uses familiar programming languages (TypeScript, Javascript, Python, Java and .NET) and that’s a great point because developers can write with the same language as the rest of their stack.
I’m starting to drift away again… What I really wanted to show in this post is how you can deploy AWS CDK applications using Azure DevOps.
Step 0 - Initial setup
The main topic of these post is about how to deploy an AWS CDK app using Azure DevOps so I’m not going to talk about how to build an AWS CDK app, also I’m going to assume that the following things are already on place:
1 - You have an AWS CDK application ready to be deployed. The application is going to be stored in an Azure DevOps Git Repository.
In my case I’m going to use an app from the aws-cdk-samples Github Repo. This one: https://github.com/aws-samples/aws-cdk-examples/tree/master/typescript/ecs/fargate-service-with-auto-scaling
2 - You have already set in your Azure DevOps a Service Connection into your AWS account.
Obviously I’m also assuming that the service connection have enough permissions to create the resources we are going to provision via CDK.
3 - You have already installed the “AWS Toolkit for Azure DevOps” installed on your Azure DevOps tenant (https://marketplace.visualstudio.com/items?itemName=AmazonWebServices.aws-vsts-tools).
Step 1 - Define the branching and deploy strategy
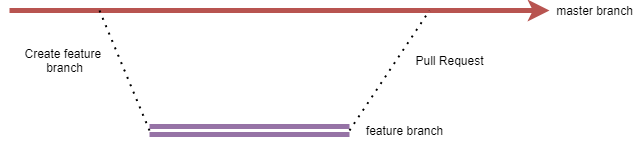
I’m going for a pretty straight-forward branch strategy.
- The master branch contains the production source code.
- Every time I want to add a new feature into my CDK app I create a new branch from the master branch.
- The new feature is integrated back onto the master branch doing a Pull Request (PR)
- We are going to build 2 Azure Pipelines.
Pipeline 1: pull request validation pipeline
The pipeline is going to be triggered when we create a PR from any branch to the master branch.
The pipeline is going to execute the following steps:
- Validate the CDK synth output using the cfn-nag (https://github.com/stelligent/cfn_nag)
- The cfn-nag tool looks for patterns in CloudFormation templates that may indicate insecure infrastructure. It will look for:
- IAM rules that are too permissive (wildcards)
- Security group rules that are too permissive (wildcards)
- Access logs that aren’t enabled
- Encryption that isn’t enabled
- Password literals.
- The cfn-nag tool looks for patterns in CloudFormation templates that may indicate insecure infrastructure. It will look for:
- Add a comment in the PR specifying with resources are going to be created, modified or deleted.
- That step is completely optional but can be quite useful because the PR reviewer can read the PR comment and know exactly how the infrastructure is going to change once he approves the PR.
Pipeline 2: master branch deployment pipeline
When the PR is approved and the code is commited into the master branch and automatic pipeline is triggered.
That pipelines is going to do the following steps:
- Deploy the code.
Step 2 - Building the PR pipeline
Let me show you the complete pipeline first:
trigger:
- none
pool:
vmImage: 'ubuntu-latest'
steps:
- task: NodeTool@0
inputs:
versionSpec: '12.x'
- task: UseRubyVersion@0
inputs:
versionSpec: '>= 2.4'
- script: |
echo "Installing packages"
sudo npm install -g aws-cdk
sudo gem install cfn-nag
displayName: 'Installing aws cdk and cfn nag'
- script: |
echo "Installing project dependencies"
sudo npm install
sudo npm run build
displayName: 'Installing project dependencies'
- task: AWSShellScript@1
inputs:
awsCredentials: 'AWS DEV ACCOUNT'
regionName: 'eu-west-1'
scriptType: 'inline'
inlineScript: |
echo "Running validations"
cdk synth -o out
cd out
fname=$(find *.template.json)
echo "Testing output with cfn-nag-scan"
cfn_nag_scan --input-path $fname
displayName: 'Validating AWS CDK output'
- task: AWSShellScript@1
inputs:
awsCredentials: 'AWS DEV ACCOUNT'
regionName: 'eu-west-1'
scriptType: 'inline'
inlineScript: |
echo "Generating CDK diff file"
cdk diff -o out -c aws-cdk:enableDiffNoFail=true --no-color "*" 2>&1 | sed -n '/Resources/,/Outputs/p' | sed 's/├/\+/g; s/│/|/g; s/─/-/g; s/└/`/g' | head -n -1 | tee output.log
sed -i '1 i\```bash' output.log
sed -i -e '$a```' output.log
displayName: 'Generating CDK diff file'
- task: PowerShell@2
displayName: "Writing Pull Request Comment"
inputs:
targetType: "inline"
script: |
try
{
Write-Host "Write Pull Request comment"
$content = Get-Content -Path .\output.log -Raw -ErrorAction Stop
$organization = "cpn"
$pullRequestThreadUrl = "https://dev.azure.com/$organization/$(System.TeamProjectId)/_apis/git/repositories/$(Build.Repository.ID)/pullRequests/$(System.PullRequest.PullRequestId)/threads?api-version=5.1"
Write-Host "PR Uri: $pullRequestThreadUrl"
if($Null -eq $content || $content -eq " " || $content -eq "")
{
$content = "CDK Diff found no resource is going to change"
}
$body = @"
{
"comments": [
{
"parentCommentId": 0,
"content": "$content",
"commentType": 1
}
],
"status": 4
}
"@
$response = Invoke-RestMethod -Uri $pullRequestThreadUrl -Method Post -Body $body -ContentType "application/json" -Headers @{Authorization = "Bearer $(System.AccessToken)"}
if ($response -ne $Null) {
Write-Host "Everything worked"
}
}
catch {
Write-Error $_
Write-Error $_.Exception.Message
}
Remember that you need to add the pipeline as a “build validation” of the master branch. A build validation validates code by pre-merging and building pull request changes.

Now, let’s try to explain step by step what the pipeline is exactly doing.
1 - We begin setting up which Node version is going to be used by the aws-cdk and which Ruby version is going to be used by the cfn-nag tool.
After setting both versions we install the aws-cdk and cfn-nag packages.
- task: NodeTool@0
inputs:
versionSpec: '12.x'
- task: UseRubyVersion@0
inputs:
versionSpec: '>= 2.4'
- script: |
echo "Installing packages"
sudo npm install -g aws-cdk
sudo gem install cfn-nag
displayName: 'Installing aws cdk and cfn nag'
2-_ In this step we’re installing the CDK app dependencies and transpiling the code.
If the CDK app was written in csharp instead of typescript we would be doing “dotnet build” instead of “npm run build”.
- script: |
echo "Installing project dependencies"
sudo npm install
sudo npm run build
displayName: 'Installing project dependencies'
3- CDK synth outputs a CloudFormation template in a concrete folder.
By default CDK Synth places the Cfn template in the cdk.out folder, but I don’t like default behaviours so I’m specifying that I want the Cfn template to be placed in a folder called out.
Afterwards I run the cfn-nag tool passing the Cfn template as a parameter.
The results of cfn-nag scan are dumped to stdout.
- A failing violation will return a non-zero exit code an stop the pipeline.
- A warning will return a zero/success exit code and the pipelines will continue the execution.
- task: AWSShellScript@1
inputs:
awsCredentials: 'AWS DEV ACCOUNT'
regionName: 'eu-west-1'
scriptType: 'inline'
inlineScript: |
echo "Running validations"
cdk synth -o out
cd out
fname=$(find *.template.json)
echo "Testing output with cfn-nag-scan"
cfn_nag_scan --input-path $fname
displayName: 'Validating AWS CDK output'
4- CDK diff compares the stack to be deployed with the already deployed stack and show the differences between both of them.
In this step I’m storing the CDK diff output in a file called “output.log”, before saving the output of the CDK diff into the file I’m applying some filters.
- task: AWSShellScript@1
inputs:
awsCredentials: 'AWS DEV ACCOUNT'
regionName: 'eu-west-1'
scriptType: 'inline'
inlineScript: |
echo "Generating CDK diff file"
cdk diff -o out -c aws-cdk:enableDiffNoFail=true --no-color "*" 2>&1 | sed -n '/Resources/,/Outputs/p' | sed 's/├/\+/g; s/│/|/g; s/─/-/g; s/└/`/g' | head -n -1 | tee output.log
sed -i '1 i\```bash' output.log
sed -i -e '$a```' output.log
displayName: 'Generating CDK diff file'
Let me explain a little the purpose of the filters:
- The CDK diff command shows quite a lot of information but I only want the information about which resources are going to be created/modified.
_sed -n '/Resources/,/Outputs/p'_
- The CDK diff output shows an output similar to the Linux “tree” command so I need to transform the tree output to ASCII otherwise when we create the PR comment we are going to find that some characters are missing.
That seems to be some kind of weird issue with the Azure Devops API.
sed 's/├/\+/g; s/│/|/g; s/─/-/g; s/└/`/g'
- Azure DevOps accepts markdown as a PR comment, so that’s exactly why I’m wrapping the output inside a markdown code block.
sed -i '1 i\```bash' output.log
sed -i -e '$a```' output.log
Let me show you an example at the how the “output.log” file looks like after applying all the filters.
```bash
[~] AWS::S3::Bucket MyFirstBucket MyFirstBucketB8884501
+- [~] DeletionPolicy
| +- [-] Retain
| `- [+] Delete
`- [~] UpdateReplacePolicy
+- [-] Retain
`- [+] Delete
```
5- The last step looks a little bit daunting but it’s quite simple.
I’m reading the “output.log” file that I created in the previous step an posting the content as a PR comment using the Azure DevOps API.
displayName: 'Generating CDK diff file'
- task: PowerShell@2
displayName: "Write Pull Request Comment"
inputs:
targetType: "inline"
script: |
try
{
Write-Host "Write Pull Request comment"
$content = Get-Content -Path .\output.log -Raw -ErrorAction Stop
$organization = "cpn"
$pullRequestThreadUrl = "https://dev.azure.com/$organization/$(System.TeamProjectId)/_apis/git/repositories/$(Build.Repository.ID)/pullRequests/$(System.PullRequest.PullRequestId)/threads?api-version=5.1"
Write-Host "PR Uri: $pullRequestThreadUrl"
if($Null -eq $content || $content -eq " " || $content -eq "")
{
$content = "CDK Diff found no resource is going to change"
}
$body = @"
{
"comments": [
{
"parentCommentId": 0,
"content": "$content",
"commentType": 1
}
],
"status": 4
}
"@
$response = Invoke-RestMethod -Uri $pullRequestThreadUrl -Method Post -Body $body -ContentType "application/json" -Headers @{Authorization = "Bearer $(System.AccessToken)"}
if ($response -ne $Null) {
Write-Host "Everything worked"
}
}
catch {
Write-Error $_
Write-Error $_.Exception.Message
}
Step 4 - Testing the PR pipeline
I have previously deployed that application : https://github.com/aws-samples/aws-cdk-examples/tree/master/typescript/ecs/fargate-service-with-auto-scaling. To test the PR pipeline I’m going to modify the CDK app by adding, updating and deleting some of its resources.
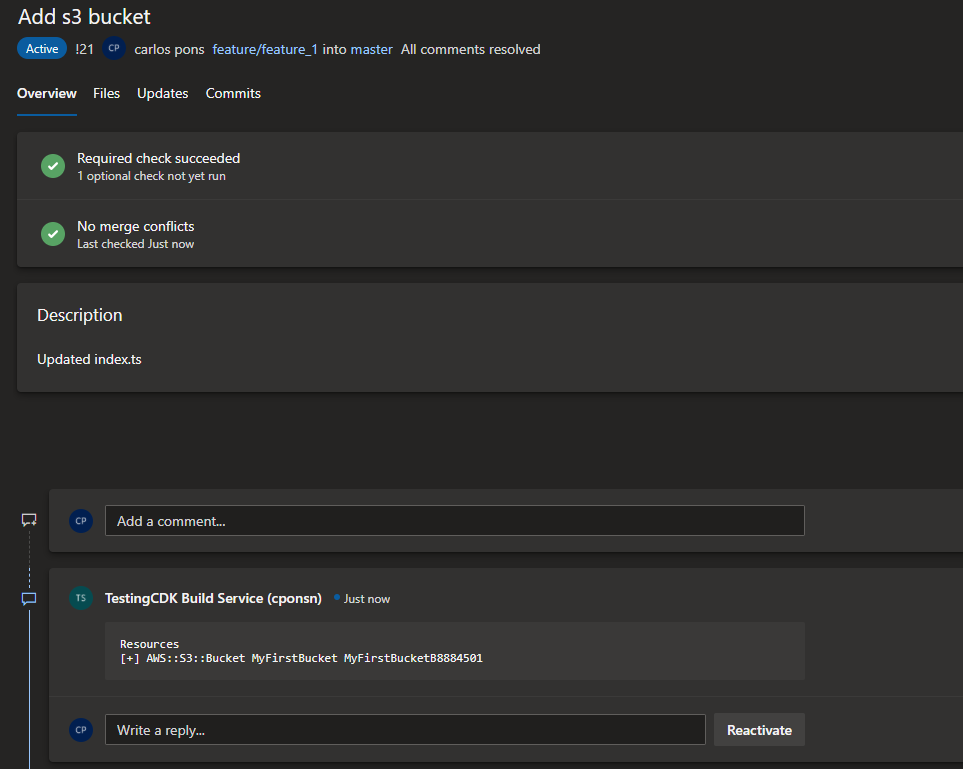
- I’ll start testing the pipeline by adding a new S3 bucket into the CDK app and creating a new PR.
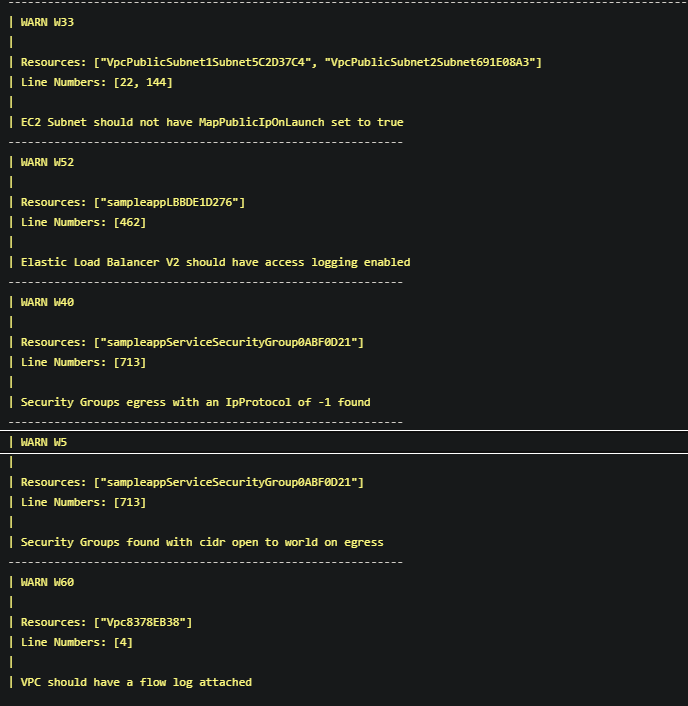
The PR pipeline finishes successfully, but if we drill inside the task where we ran the cfn-nag scan we can see that we have some security warnings that maybe we should try to fix.
Also if we take a look at the PR comment section a new comment has been created by the pipeline agent.
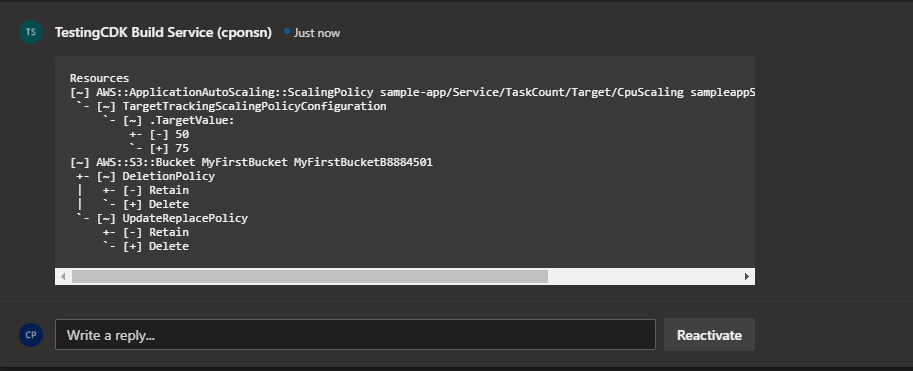
- Next I’m going to modify the autoscaling policy and the s3 bucket removal policy.
After applying the changes in the CDK app I create a new PR.
The pipeline finishes successfully and if we take a look at the PR section we can see a new comment has been created.
- Next I’m going to delete the s3 bucket, put the autoscaling policy back to the original value and create a new SNS topic.
After applying the changes in the CDK app I create a new PR.
The PR pipeline ends correctly and if we take a look at the PR section we can see a new comment has been created.
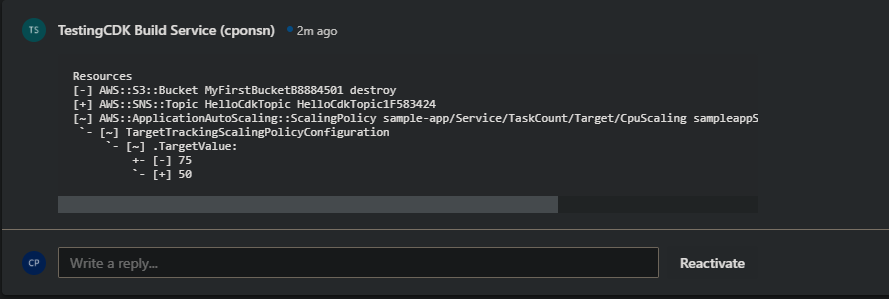
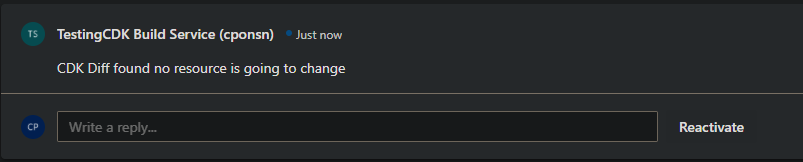
- Finally I’m going to tidy a little bit the CDK app and do some code refactoring but I’m not going to modify any AWS resource. After applying some code refactor I create a new PR.
The PR pipeline ends correctly and if we take a look at the PR section we can see a new comment has been created and is telling us that no resource is going to be modified.
Step 5 - Building the master branch integration pipeline
The pipeline will be triggered when the PR is completed and the code is commited to the master branch.
trigger:
branches:
include:
- master
paths:
exclude:
- 'azure-pipelines-pr.yml'
- 'azure-pipelines.yml'
pool:
vmImage: 'ubuntu-latest'
steps:
- script: |
echo "Installing packages"
sudo npm install -g aws-cdk
displayName: 'Installing aws cdk'
- script: |
echo "Installing project dependencies"
sudo npm install
sudo npm run build
displayName: 'Installing project dependencies'
- task: AWSShellScript@1
inputs:
awsCredentials: 'AWS DEV ACCOUNT'
regionName: 'eu-west-1'
scriptType: 'inline'
inlineScript: |
echo "Deploying App"
cdk deploy --ci --require-approval never
displayName: 'Deploying CDK app'
Let me explain every step that the pipeline does.
1 - First of all I need to exclude the pipeline files because I don’t want to trigger this pipeline if I’m only updating the YAML files.
trigger:
branches:
include:
- master
paths:
exclude:
- 'azure-pipelines-pr.yml'
- 'azure-pipelines.yml'
2 - We are doing exactly the same steps as the previous pipeline:
- Setting up the Node version for the AWS CDK package.
- Installing the AWS-CDK package.
- Installing the application dependencies.
- script: |
echo "Installing packages"
sudo npm install -g aws-cdk
displayName: 'Installing aws cdk'
- script: |
echo "Installing project dependencies"
sudo npm install
sudo npm run build
displayName: 'Installing project dependencies'
3 - Finally we’re deploying the app.
If the CDK needs to create any security resource like IAM users you need to add the flag “–require-approval never”, otherwise is going to fail.
You might want to add a manual intervention step before doing the deploy, in that case you should create an “Environment” and convert that step into a deployment job.
More info here: https://docs.microsoft.com/en-us/azure/devops/pipelines/process/environments?view=azure-devops
- task: AWSShellScript@1
inputs:
awsCredentials: 'AWS DEV ACCOUNT'
regionName: 'eu-west-1'
scriptType: 'inline'
inlineScript: |
echo "Deploying App"
cdk deploy --ci --require-approval never
displayName: 'Deploying CDK app'